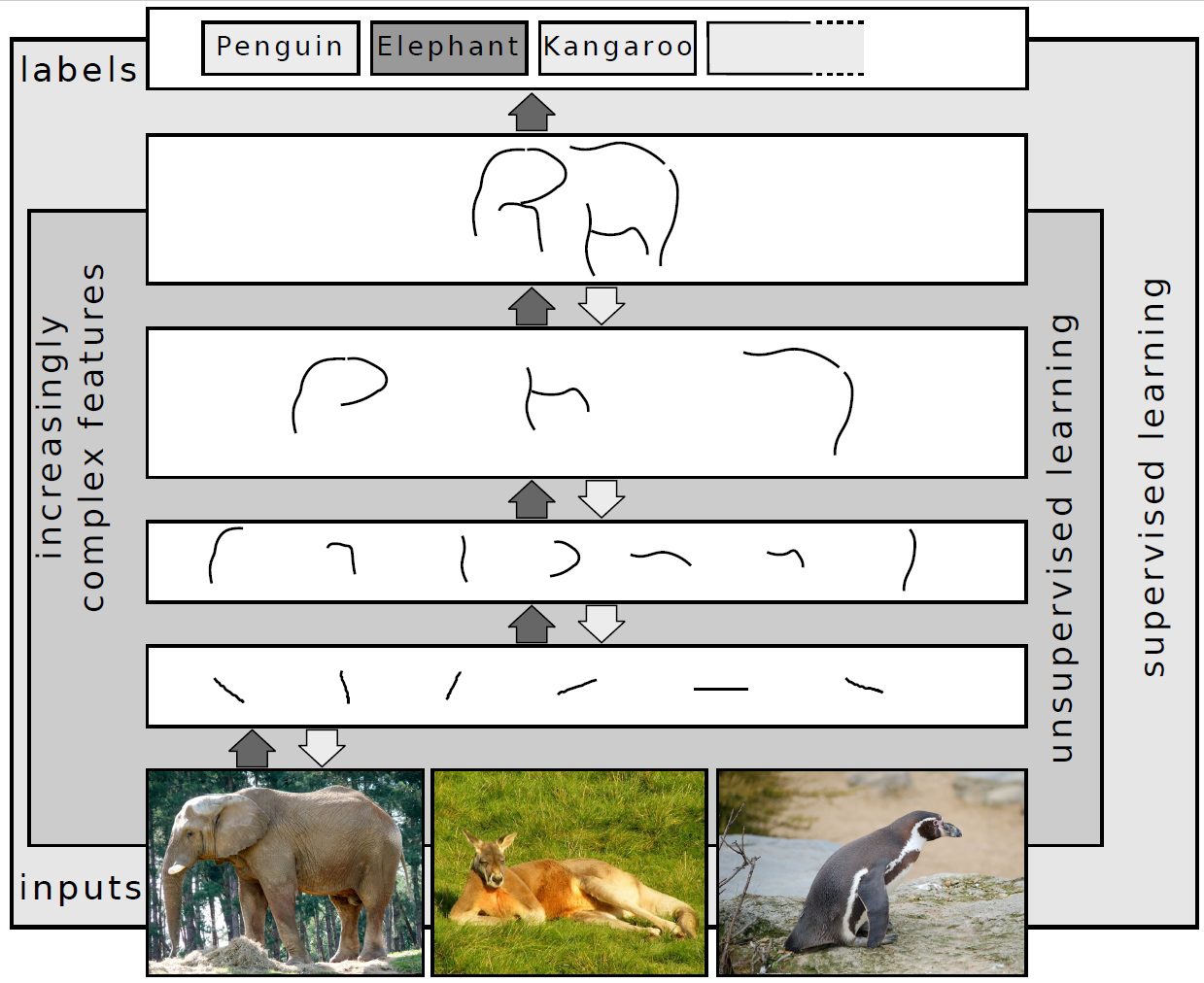
A mély tanulás lényege: sok rétegű hálózat, amely hierarchikus reprezentációkat épít fel nyers adatokból. Forrás: Wikimedia Commons, CC BY-SA 4.0.
Mély tanulás és hagyományos gépi tanulás
A mély tanulás (deep learning) a gépi tanulás egy ága, amelyre a sok rétegű neurális hálózatok jellemzők. A hagyományos gépi tanulási módszerektől abban különbözik, hogy a jellemzők kinyerése (feature engineering) nem kézzel történik: a hálózat maga tanulja meg, milyen belső reprezentációk hasznosak a feladathoz.
Ez különösen akkor számít, ha az adatok természetes struktúrájuk miatt nehezen írhatók le kézzel definiált jellemzőkkel: nyers képpixelek, audio hullámformák vagy nyers szöveg esetén.
Konvolúciós neurális hálózatok (CNN)
A konvolúciós hálózatok (Convolutional Neural Networks, CNN) a képfeldolgozás és számítógépes látás alapmodelljei. A tanulható konvolúciós szűrők lokális mintákat ismernek fel a bemeneti képen — az alsó rétegek éleket és textúrákat, a felsők összetett objektumrészeket tanulnak meg.
A főbb CNN architektúrák:
- LeNet-5 (1998): az egyik első gyakorlati CNN, kézírásfelismerésre.
- AlexNet (2012): GPU-alapú betanítással nyert ImageNet versenyen, a modern mélytanulási hullám elindítója.
- ResNet (2015): maradékkapcsolatok (residual connections) révén nagyon mély hálók is stabilan taníthatók.
- EfficientNet: skálázható architektúra, amely mélység, szélesség és felbontás egyensúlyára optimalizál.

Egyszerű előrecsatolt hálózat — a CNN ennél több réteget és speciális konvolúciós szűrőket tartalmaz. Forrás: Wikimedia Commons, CC BY-SA 3.0.
Rekurrens hálózatok és LSTM
A rekurrens neurális hálózatok (RNN) szekvenciális adatok feldolgozására terveztek. A rejtett állapot az előző időlépés információját is hordozza, így a hálózat „memóriával" rendelkezik. Szövegek, idősorok és hangjelek modellezésére alkalmazzák.
Az egyszerű RNN-ek hosszú szekvenciáknál eltűnő gradiensekkel küzdenek. Ezt a problémát oldotta meg az LSTM (Long Short-Term Memory), amely kapu-mechanizmusokkal vezérli, mi maradjon meg a memóriában és mi törlődjön ki.
import torch
import torch.nn as nn
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size,
num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
out, _ = self.lstm(x)
return self.fc(out[:, -1, :])
Transzformer architektúra
A 2017-ben megjelent „Attention Is All You Need" tanulmány bevezette a transzformer architektúrát, amely felváltotta az RNN-alapú modelleket a természetesnyelv-feldolgozásban. Az önfigyelem (self-attention) mechanizmus révén a modell párhuzamosan vizsgálja a szekvencia összes elemét, és közvetlen kapcsolatot tud kialakítani távoli elemek között is.
A transzformer alapú modellek (BERT, GPT, T5) azóta a szövegfeldolgozás, fordítás, szöveggenerálás és kérdésválaszolás területén elterjedtek. A vision transformer (ViT) ugyanezt a mechanizmust alkalmazza képfelismerésre.
Transfer learning és fine-tuning
A mély tanulásban általánosan alkalmazott megközelítés: egy nagy adathalmazon előtanított modell súlyait átvesszük, majd kisebb, célspecifikus adathalmazon tovább finomítjuk (fine-tuning). Ez lényegesen kevesebb adatot és számítási erőforrást igényel, mint az alaptól való tanítás.
Keretrendszerek és eszközök
A mély tanulás fejlesztéséhez az alábbi nyílt forráskódú eszközök a legelterjedtebbek:
- PyTorch — dinamikus számítási gráf, kutatásban és iparban egyaránt vezető pozíció. A Meta AI fejleszti aktívan.
- TensorFlow — statikus és dinamikus gráf is támogatott; a Google fejlesztette ki, termelési rendszerekben széles körben alkalmazzák.
- Keras — magas szintű API TensorFlow felett, gyors prototípus-fejlesztéshez.
- Hugging Face Transformers — előtanított transzformer modellek letöltése és finomhangolása néhány sorban.
Mély tanulás hazai kontextusban
Magyarországon a mély tanulás legintenzívebben az orvosi képdiagnosztika és az ipari minőségellenőrzés területein jelenik meg. A Pécsi Tudományegyetem, a Semmelweis Egyetem, valamint a BME különböző tanszékein publikáltak konvolúciós hálózatokon alapuló diagnosztikai kutatásokat, elsősorban bőrgyógyászati és radiológiai képek elemzésére.
Az autóipari szektorban a Magyarországon működő gyártóüzemek (Audi Győr, Mercedes-Benz Kecskemét) anyacégeiken keresztül részesei az autonóm vezető rendszerek mélytanulás-alapú fejlesztéseinek, amelyek a kamerarendszerek képfelismerő komponenseit tartalmazzák.
A mély tanulás nem alkalmazható mindenre — kis adathalmazokon, értelmezhetőségi igény esetén vagy szigorúan szabályozott területeken a klasszikus módszerek ma is versenyképesek maradnak.
Utoljára frissítve: 2025. május 9. — A tartalom nyilvánosan elérhető forrásokra támaszkodik.